3. Environmental Data Sampling
Hannah L. Owens
Carsten Rahbek
2026-07-23
Source:vignettes/c_DataSampling.Rmd
c_DataSampling.RmdIntroduction
As stated in the introduction
to this package, one of the key contributions of
voluModel is the way it handles the extraction of
environmental data for niche modeling. Specifically, environmental data
at presences, absences, pseudoabsences, and/or background points can be
extracted from environmental data multi-layer SpatRaster
objects based on depth in addition to horizontal coordinates. Another
useful tool provided with voluModel is
marineBackground(), which helps the user generate training
regions from which background or pseudoabsence data are drawn. This is
where we will start, so let’s get into it.
Here are the packages you will need.
3D Data Extraction
First, we will cover how to extract environmental data from a
multi-layer SpatRaster object using 3D occurrence
coordinates. The species occurrences I will use are Steindachneria
argentea, Luminous Hake, data downloaded via R (R Core Team, 2020)
from GBIF (Chamberlain et al., 2021; Chamberlain and Boettiger,
2017) and OBIS (Provoost and Bosch, 2019) via occCite
(Owens et al., 2021).
# Get points
occs <- read.csv(system.file("extdata/Steindachneria_argentea.csv",
package='voluModel'))
occurrences <- occs %>%
dplyr::select(decimalLongitude, decimalLatitude, depth) %>%
dplyr::distinct() %>%
dplyr::filter(depth %in% 1:2000)The environmental dataset I will use as an example is temperature (Locarnini et al., 2018) from the World Ocean Atlas (WOA; Garcia et al., 2019). I have chosen to focus on temperature for simple illustrative purposes–we recommend you explore additional variables from the World Ocean Atlas and other sources. These data are supplied by the World Ocean Atlas as point shapefiles; the version supplied here has been cropped between -110 and -40 longitude and between -5 and 50 latitude to make it more memory-efficient.
This chunk of code loads the example data shapefile, which results in
a SpatVector:
# Temperature
td <- tempdir()
unzip(system.file("extdata/woa18_decav_t00mn01_cropped.zip",
package = "voluModel"),
exdir = paste0(td, "/temperature"), junkpaths = T)
temperature <- vect(paste0(td, "/temperature/woa18_decav_t00mn01_cropped.shp"))
# Looking at the dataset
as.data.frame(temperature[1:5,1:10])## SURFACE d5M d10M d15M d20M d25M d30M d35M d40M d45M
## 1 23.575 23.392 22.919 22.318 21.766 21.117 20.531 19.860 19.266 18.673
## 2 23.204 22.979 22.559 22.057 21.401 20.651 19.978 19.433 18.835 18.247
## 3 23.451 23.125 22.726 22.134 21.520 20.828 20.128 19.472 18.875 18.353
## 4 23.261 22.968 22.559 22.052 21.528 20.945 20.337 19.759 19.198 18.669
## 5 22.977 22.790 22.463 22.036 21.611 21.079 20.521 20.000 19.423 18.835As you can see, each point in the SpatVector is a line
in the associated data.frame; each column is a depth layer
at that point–“d5M” translates to “5 meters deep”. For more details on
how to process environmental data, see the
raster data tutorial. This next chunk converts the
SpatVector to a multi-layer SpatRaster; the
layers of the multi-layer SpatRaster are then named the
same as the column names of the SpatVector. I strip the “d”
and “M” from the column names so they are a little easier to use as
depth coordinates.
# Creating a SpatRaster vector
template <- centerPointRasterTemplate(temperature)
tempTerVal <- rasterize(x = temperature, y = template, field = names(temperature))
# Get names of depths
envtNames <- gsub("[d,M]", "", names(temperature))
envtNames[[1]] <- "0"
names(tempTerVal) <- envtNames
temperature <- tempTerVal
rm(tempTerVal)At this point, you may have noticed a message popping up about which
columns voluModel is interpreting as coordinates.
voluModel is fairly flexible in how the coordinate columns
are named, and it relies on names instead of column position to
interpret x, y, and z (or latitude, longitude, and depth) coordinates.
We do this to make voluModel as flexible as possible to a
diversity of input formats, although English is the only supported
language at the moment. Here are some examples of names that work.
occsTest <- occurrences[19:24,]
xyzSample(occs = occsTest, envBrick = temperature)## Using decimalLongitude, decimalLatitude, and depth
## as x, y, and z coordinates, respectively.## [1] 25.770 15.091 NA 9.137 NA NA## Using x, y, and z
## as x, y, and z coordinates, respectively.## [1] 25.770 15.091 NA 9.137 NA NA
rm(occsTest)One common step in a niche modeling workflow is to down-sample
occurrence data to the same resolution as the environmental data. We do
this to avoid over-fitting the model due to biased sampling. The next
chunk of code downsamples occurrence points so that there is only one
per voxel (i.e. 3D pixel) of environmental data. It does this by looping
through each layer of the multi-layer SpatRaster, selecting
the occurrence points with depths closest to the depths represented by
the corresponding layer in the SpatRaster vector. I then
downsample these points using voluModel’s
downsample() function.
# Gets the layer index for each occurrence by matching to depth
layerNames <- as.numeric(names(temperature))
occurrences$index <- unlist(lapply(occurrences$depth, FUN = function(x) which.min(abs(layerNames - x))))
indices <- unique(occurrences$index)
downsampledOccs <- data.frame()
for(i in indices){
tempPoints <- occurrences[occurrences$index==i,]
tempPoints <- downsample(tempPoints, temperature[[1]])
tempPoints$depth <- rep(layerNames[[i]], times = nrow(tempPoints))
downsampledOccs <- rbind(downsampledOccs, tempPoints)
}
occurrences <- downsampledOccs
head(occurrences)## decimalLongitude decimalLatitude depth
## 1 -54.5 7.5 450
## 2 -82.5 12.5 450
## 3 -93.5 19.5 450
## 4 -97.5 22.5 450
## 5 -82.5 23.5 450
## 6 -89.5 23.5 450
print(paste0("Original number of points: ", nrow(occs), "; number of downsampled occs: ", nrow(occurrences)))## [1] "Original number of points: 301; number of downsampled occs: 71"The resampled points returned by downsample() are
horizontally centered in each voxel. The red dots in the plot show
occurrences from the original dataset; the orange dots show the
downsampled dataset. Not all of the orange dots may be visible
underneath the red dots.
land <- rnaturalearth::ne_countries(scale = "small", returnclass = "sf")[1]
pointCompMap(occs1 = occs, occs2 = occurrences,
occs1Name = "original", occs2Name = "cleaned",
spName = "Steindachneria argentea",
land = land, verbose = FALSE)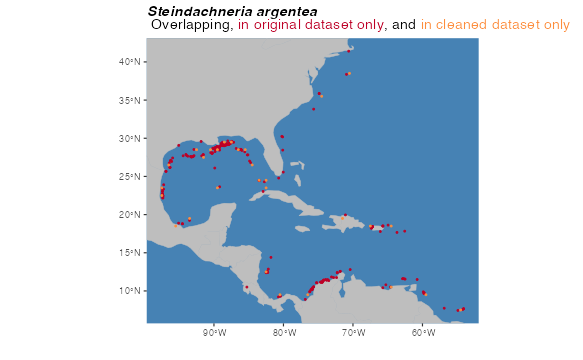
At this point, we can demonstrate one of the key contributions of
voluModel– an improvement in how the environmental data are
extracted at species’ occurrences. voluModel samples
environmental conditions at the depth where each record was located,
instead of extrapolating to surface or bottom conditions. Finally, we
add a column called “response” and fill it by repeating “1”, to signify
that these occurrences should be interpreted as presences for the
purposes of modeling.
# Extraction
occurrences$temperature <- xyzSample(occs = occurrences, envBrick = temperature)## Using decimalLongitude, decimalLatitude, and depth
## as x, y, and z coordinates, respectively.
# Add "response" column for modeling
occurrences$response <- rep(1, times = nrow(occurrences))
occurrences <- occurrences[complete.cases(occurrences),]
head(occurrences)## decimalLongitude decimalLatitude depth temperature response
## 3 -93.5 19.5 450 9.137 1
## 5 -82.5 23.5 450 11.395 1
## 6 -89.5 23.5 450 9.285 1
## 7 -84.5 26.5 450 9.145 1
## 9 -91.5 27.5 450 9.091 1
## 15 -89.5 28.5 80 20.440 1In a “real” modeling scenario, you would extract all your
environmental variables using xyzSample(), then add the
response column. Or add the response column first or in the middle. I’m
not the boss of you.
Generating Repeatable Training Regions
To generate a sample of pseudoabsences and/or background points, it is important to consider the environments the species of interest can access (Barve et al., 2011). There is ample discussion in the literature on how to best delimit a niche model training region (also variously called M or the background region), and we will not review the issue here. In the absence of specific information on species’ dispersal capabilities, algorithmically generating a repeatable sampling background from a clear set of rules may be suitable approximation, or a jumping-off point for hand-curating training regions in a GIS software of choice.
We designed marineBackground() as a wrapper around , a
function provided by the rangeBuilder package
(Davis-Rabosky et al., 2016) which generates background
sampling regions by fitting an alpha hull polygon around an occurrence
point dataset. Let’s look at how marineBackground() (and by
extension getDynamicAlphaHull()) fits alpha hull polygons,
based on the cleaned species occurrence data from above.
getDynamicAlphaHull(), which is run within
marineBackground() generates a polygon (or polygons) that
can be used as a training region by fitting an alpha hull (or hulls)
around an occurrence dataset. Alpha is a parameter that controls the
complexity of the polygon(s) that is being fit around the occurrences.
getDynamicAlphaHull() adjusts the alpha parameter
iteratively, until it meets criteria the user can set via the arguments
fraction, which is the minimum fraction of occurrences that
must be contained within the polygon(s), partCount, which
is the maximum number of polygons generated to fit the data, and
buff, which is the permissible distance from a point to the
edge of a polyon in meters. marineBackground() takes these
and many of the same other arguments as
getDynamicAlphaHull(). Here’s how it works.
trainingRegion <- marineBackground(occurrences,
fraction = 1,
partCount = 1,
buff = 1000000,
clipToOcean = F)
plot(trainingRegion, border = F, col = "gray",
main = "100% Points,\nMax 1 Polygon Permitted, 100 km Buffer",
axes = T)
plot(land, col = "black", add = T)
points(occurrences[,c("decimalLongitude", "decimalLatitude")],
pch = 20, col = "red", cex = 1.5)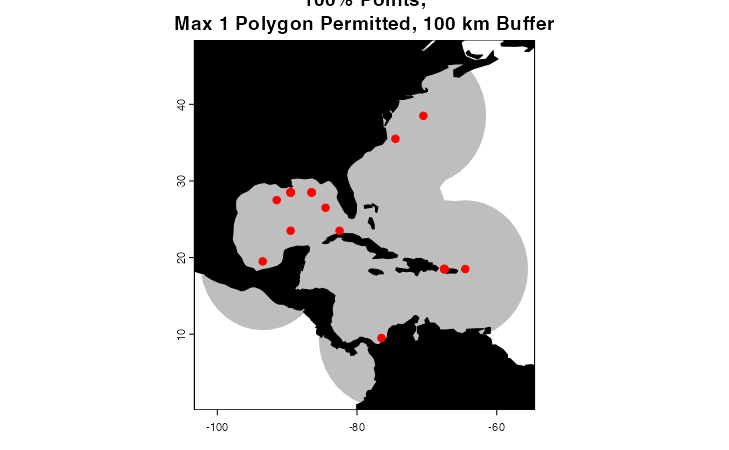
What parameters you choose to fit the alpha hull will depend on the
biology of the organism you are trying to model (e.g. you may choose a
much smaller buffer for a sessile organism than you would for a highly
vagile migratory species), your data, and the particulars of your study
system and the geography of your study area. You may need to experiment
to find something that looks sensible. If you do not provide a
pre-defined buffer, marineBackground() will calculate a
buffer that is the mean of the top and bottom 10% of distances between
points in the dataset.
You may have noticed that the training regions in the above examples
include some areas of the Pacific where the species has not been
observed, and cannot access. This could cause problems if it is used to
train your model. You could delete this area by hand in your
favorite GIS software, OR you could change clipToOcean to
TRUE in marineBackground(), and any polygon
fragments that do not contain an occurrence will be deleted
automatically. This is a key difference from
getDynamicAlphaHull().
trainingRegion <- marineBackground(occurrences,
buff = 1000000,
clipToOcean = T)
plot(trainingRegion, border = F, col = "gray",
main = "100 km Buffer,\nClipped to Occupied Polygon",
axes = T)
plot(land, col = "black", add = T)
points(occurrences[,c("decimalLongitude", "decimalLatitude")],
pch = 20, col = "red", cex = 1.5)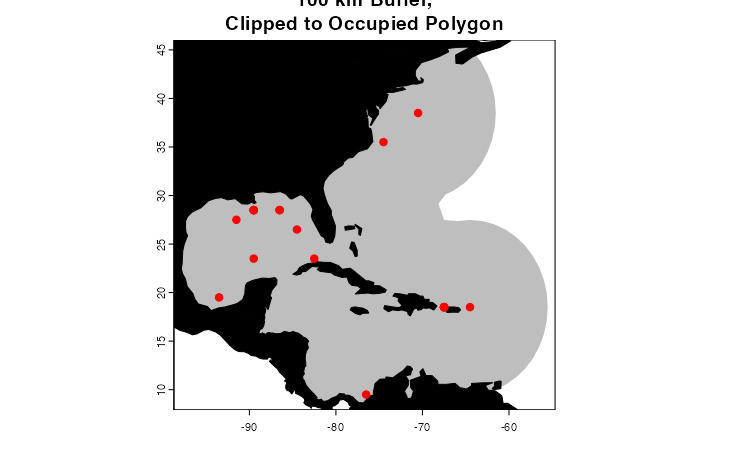
The last major difference between marineBackground() and
getDynamicAlphaHull() is how the functions handle training
regions that are adjacent to the antimeridian (i.e. 180° E or W).
getDynamicAlphaHull() truncates polygons at this line,
which can lead to some strange-looking training areas or fatal errors.
marineBackground(), on the other hand, wraps polygons
across the meridian and merges them if they overlap. For this example, I
am going to manipulate the longitudinal coordinates of our Luminous Hake
dataset to generate a quick fictional example.
# Fictional example occurrences
pacificOccs <- occurrences
pacificOccs$decimalLongitude <- pacificOccs$decimalLongitude - 100
for (i in 1:length(pacificOccs$decimalLongitude)){
if (pacificOccs$decimalLongitude[[i]] < -180){
pacificOccs$decimalLongitude[[i]] <- pacificOccs$decimalLongitude[[i]] + 360
}
}
# marine Background
pacificTrainingRegion <- marineBackground(pacificOccs,
fraction = 0.95, partCount = 3,
buff = 1000000,
clipToOcean = T)
plot(pacificTrainingRegion, border = F, col = "gray",
main = "marineBackground\nAntimeridian Wrap",
axes = T)
plot(land, col = "black", add = T)
points(pacificOccs[,c("decimalLongitude", "decimalLatitude")],
pch = 20, col = "red", cex = 1.5)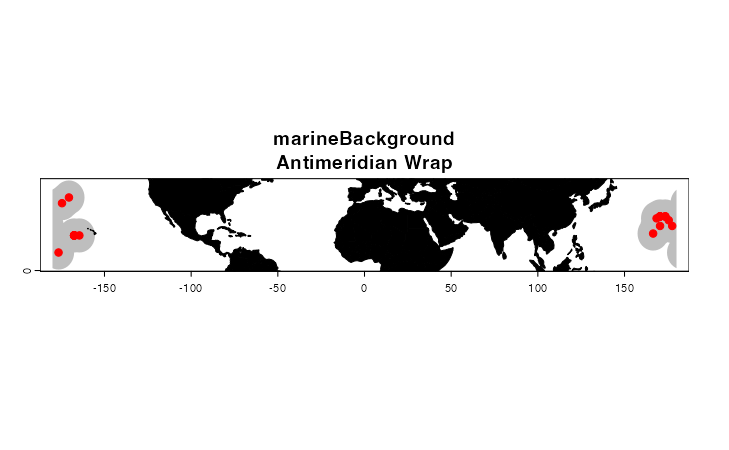
Background Data Extraction
As discussed above, some modeling methods require the generation of a
sampling region from which training/pseudoabsence/background points are
drawn. The training region should approximately answer the question
“What environments are most likely to have been experienced by Lumious
Hakes?” Our answer to this question for the purposes of this tutorial is
represented in trainingRegion, which we generated above
using marineBackground(). Next, we generate 3D training
points within this region using the mSampling3D() function.
The function takes an occurrence data.frame, a multi-layer
SpatRaster that will serve as a template for the resolution
of the training points, a SpatialPolygons object
representing the training region, and, optionally, information on the
range of depths from which the function should sample. If you have
reason to believe the species you are modeling can access depths higher
or lower than those represented by occurrences, you can specify a
maximum and minimum training depth from which to draw occurrence points.
mSampling3D() by default draws training points from the
full depth extent of the supplied multi-layer
SpatRaster.
For this example, I am sampling training points from 50 to 1500 m.
# Background
backgroundVals <- mSampling3D(occs = occurrences,
envBrick = temperature,
mShp = trainingRegion,
depthLimit = c(50, 1500))## Using decimalLongitude, decimalLatitude, and depth
## as x, y, and z coordinates, respectively.
backgroundVals$temperature <- xyzSample(occs = backgroundVals, temperature)## Using decimalLongitude, decimalLatitude, and depth
## as x, y, and z coordinates, respectively.
#Remove incomplete cases
backgroundVals <- backgroundVals[complete.cases(backgroundVals),]Once the points are sampled, we add a column called “response” and fill it by repeating “0”, to signify that these occurrences should be interpreted as absences for the purposes of modeling.
# Add "response" column for modeling
backgroundVals$response <- rep(0, times = nrow(backgroundVals))
head(backgroundVals)## decimalLongitude decimalLatitude depth temperature response
## 73 -68.5 43.5 50 6.473 0
## 74 -67.5 43.5 50 6.669 0
## 75 -66.5 43.5 50 6.779 0
## 77 -64.5 43.5 50 3.679 0
## 78 -63.5 43.5 50 4.003 0
## 79 -62.5 43.5 50 5.038 0It is important to note that this background data represents EVERY voxel within the training region that is not occupied by observances. Depending on your study design and the modeling algorithm you are using, these data will need to be subsampled. You could choose a random sample, select points based on geography, or any number of other strategies. Below is just one example–weighting the background points by their environmental dissimilarity to the Luminous Hake occurrence points. This manner of downsampling may be appropriate for modeling methods that interpret training points as pseudoabsences, such as generalized linear modeling, but will lead to overfit models when using algorithms like Maxent.
# Sample background points weighted by distance from mean of occurrence temperatures
meanTemp <- mean(occurrences[,c("temperature")])
backgroundVals$distance <- abs(backgroundVals[,"temperature"] - meanTemp)
backgroundVals$sampleWeight <- (backgroundVals$distance -
min(backgroundVals$distance))/(max(backgroundVals$distance) -
min(backgroundVals$distance))
sampleForAbsence <- sample(x = rownames(backgroundVals),
size = nrow(occurrences) * 100,
prob = backgroundVals$backgroundVals)
backgroundVals <- backgroundVals[match(sampleForAbsence,
rownames(backgroundVals)),]
backgroundVals$response <- as.factor(backgroundVals$response)
# Unite datasets and see how things look
dataForModeling <- rbind(occurrences, backgroundVals[,colnames(occurrences)])
ggplot(dataForModeling, aes(x = temperature, fill = response, color = response)) +
geom_density(alpha = .6) +
scale_color_manual(values=c("#999999", "#E69F00"),
labels = c("Pseudoabsence", "Presence")) +
scale_fill_manual(values=c("#999999", "#E69F00"),
labels = c("Pseudoabsence", "Presence")) +
labs(title="Temperature Sampling Density,\nOccurrences vs. Pseudoabsences",
x="Temperature (C)", y = "Density")+
theme_classic()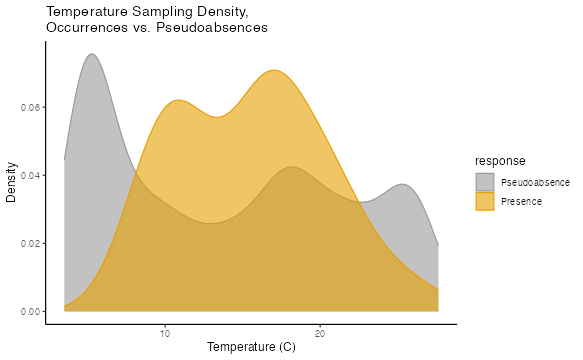
For a more complex, multivariate example of environmental dissimilarity weighting, refer to the GLM workflow.
Tidying up
Last, we need to close the temporary directory we opened when we opened the data.
unlink(td, recursive = T)References
Bakis Y (2021): TU_Fish. v1.1. No organization. Dataset/Occurrence. https://web.archive.org/web/20221202141213/https://bgnn.tulane.edu/ipt/resource?r=tu_fish&v=1.1 Accessed via OBIS on 2020-11-04.
Bentley A (2022). KUBI Ichthyology Collection. Version 17.80. University of Kansas Biodiversity Institute. DOI: 10.15468/mgjasg. Accessed via GBIF on 2020-10-13.
Bentley A (2022). KUBI Ichthyology Tissue Collection. Version 18.68. University of Kansas Biodiversity Institute. DOI: 10.15468/jmsnwg. Accessed via GBIF on 2020-10-13.
Buckup P A (2022). Coleção Ictiológica (MNRJ), Museu Nacional (MN), Universidade Federal do Rio de Janeiro(UFRJ). Version 157.1487. Museu Nacional / UFRJ. DOI: 10.15468/lluzfl. Accessed via GBIF on 2020-10-13.
Catania D, Fong J (2022). CAS Ichthyology (ICH). Version 150.300. California Academy of Sciences. DOI: 10.15468/efh2ib. Accessed via GBIF on 2020-10-13.
Chakrabarty P (2019). LSUMZ (LSU MNS) Fishes Collection. Version 2.2. Louisiana State University Museum of Natural Science. DOI: 10.15468/gbnym3. Accessed via GBIF on 2020-10-13.
Chamberlain S, Barve V, Mcglinn D, Oldoni D, Desmet P, Geffert L, Ram K (2021). rgbif: Interface to the Global Biodiversity Information Facility API. R package version 3.6.0, https://CRAN.R-project.org/package=rgbif.
Chamberlain S, Boettiger C (2017). “R Python, and Ruby clients for GBIF species occurrence data.” PeerJ PrePrints. DOI: 10.7287/peerj.preprints.3304v1.
Davis-Rabosky AR, Cox CL, Rabosky DL, Title PO, Holmes IA, Feldman A, McGuire JA (2016). Coral snakes predict the evolution of mimicry across New World snakes. Nature Communications 7:11484. DOI: 10.1038/ncomms11484
Espinosa Pérez H, Comisión nacional para el conocimiento y uso de la biodiversidad C (2021). Computarización de la Colección Nacional de Peces del Instituto de Biología UNAM. Version 1.9. Comisión nacional para el conocimiento y uso de la biodiversidad. DOI: 10.15468/zb2odl. Accessed via GBIF on 2020-10-13.
Frable B (2019). SIO Marine Vertebrate Collection. Version 1.7. Scripps Institution of Oceanography. DOI: 10.15468/ad1ovc. Accessed via GBIF on 2020-10-13.
Fishnet2 Portal, http://www.fishnet2.net, Accessed via OBIS on 2020-11-04.
Froese, R. and D. Pauly. Editors. 2020. FishBase. World Wide Web electronic publication. www.fishbase.org, version (xx/200x). Accessed via OBIS on 2020-11-04.
Gall L (2021). Vertebrate Zoology Division - Ichthyology, Yale Peabody Museum. Yale University Peabody Museum. DOI: 10.15468/mgyhok. Accessed via GBIF on 2020-10-13.
García, CB, and Duarte, LO, ‘Columbian Caribbean Sea’, in J.H. Nicholls (comp.) HMAP Data Pages https://figshare.com/articles/dataset/HMAP_Dataset_18_Colombian_Caribbean_Sea/23504046 Accessed via OBIS on 2020-11-04.
Garcia HE, Weathers K, Paver CR, Smolyar I, Boyer TP, Locarnini RA, Zweng MM, Mishonov AV, Baranova OK, Seidov D, Reagan JR (2018). World Ocean Atlas 2018, Volume 3: Dissolved Oxygen, Apparent Oxygen Utilization, and Oxygen Saturation. A Mishonov Technical Ed.; NOAA Atlas NESDIS 83, 38pp.
GBIF.org (24 September 2020) GBIF Occurrence Download DOI: 10.15468/dl.efuutj.
Grant S, McMahan C (2020). Field Museum of Natural History (Zoology) Fish Collection. Version 13.12. Field Museum. DOI: 10.15468/alz7wu. Accessed via GBIF on 2020-10-13.
Harvard University M, Morris P J (2022). Museum of Comparative Zoology, Harvard University. Version 162.296. Museum of Comparative Zoology, Harvard University. DOI: 10.15468/p5rupv. Accessed via GBIF on 2020-10-13.
Hendrickson D A, Cohen A E, Casarez M J (2022). University of Texas, Biodiversity Center, Ichthyology Collection (TNHCi). Version 5.175. University of Texas at Austin, Biodiversity Collections. DOI: 10.15468/h8gxdr. Accessed via GBIF on 2020-10-13.
INVEMAR (2022). SIBM en línea: Sistema de Información sobre Biodiversidad Marina. Santa Marta: Instituto de investigaciones Marinas y Costeras José Benito Vives de Andréis,. https://siam.invemar.org.co/ Accessed via OBIS on 2020-11-04.
Locarnini RA, Mishonov AV, Baranova OK, Boyer TP, Zweng MM, Garcia HE, Reagan JR, Seidov D, Weathers K, Paver CR, Smolyar I (2018). World Ocean Atlas 2018, Volume 1: Temperature. A. Mishonov Technical Ed.; NOAA Atlas NESDIS 81, 52pp.
McLean, M.W. (2014). Straightforward Bibliography Management in R Using the RefManager Package. NA, NA. https://arxiv.org/abs/1403.2036.
McLean, M.W. (2017). RefManageR: Import and Manage BibTeX and BibLaTeX References in R. The Journal of Open Source Software.
Mertz W (2021). LACM Vertebrate Collection. Version 18.9. Natural History Museum of Los Angeles County. DOI: 10.15468/77rmwd. Accessed via GBIF on 2020-10-13.
Nakae M, Shinohara G (2018). Fish collection of National Museum of Nature and Science. National Museum of Nature and Science, Japan. Occurrence dataset DOI: 10.15468/w3dzv1 accessed via GBIF.org on yyyy-mm-dd. Accessed via OBIS on 2020-11-04.
Natural History Museum (2021). Natural History Museum (London) Collection Specimens. DOI: 10.5519/0002965. Accessed via GBIF on 2020-10-13.
National Museum of Natural History, Smithsonian Institution NMNH Fishes Collection Database (2007). National Museum of Natural History, Smithsonian Institution, 10th and Constitution Ave. N.W., Washington, DC 20560-0193. Accessed via OBIS on 2020-11-04.
Norén M, Shah M (2017). Fishbase. FishBase. DOI: 10.15468/wk3zk7. Accessed via GBIF on 2020-10-13.
Norton B, Hogue G (2021). NCSM Ichthyology Collection. Version 22.8. North Carolina State Museum of Natural Sciences. DOI: 10.36102/dwc.1. Accessed via GBIF on 2020-10-13.
Nychka D, Furrer R, Paige J, Sain S (2021). “fields: Tools for spatial data.” R package version 13.3. https://github.com/dnychka/fieldsRPackage.
Orrell T, Informatics Office (2021). NMNH Extant Specimen Records (USNM, US). Version 1.49. National Museum of Natural History, Smithsonian Institution. DOI: 10.15468/hnhrg3. Accessed via GBIF on 2020-10-13.
Owens H, Merow C, Maitner B, Kass J, Barve V, Guralnick R (2021). occCite: Querying and Managing Large Biodiversity Occurrence Datasets. doi: 10.5281/zenodo.4726676, R package version 0.4.9.9000, https://CRAN.R-project.org/package=occCite.
Prestridge H (2021). Biodiversity Research and Teaching Collections - TCWC Vertebrates. Version 9.4. Texas A&M University Biodiversity Research and Teaching Collections. DOI: 10.15468/szomia. Accessed via GBIF on 2020-10-13.
Provoost P, Bosch S (2019). “robis: R Client to access data from the OBIS API.” Ocean Biogeographic Information System. Intergovernmental Oceanographic Commission of UNESCO. R package version 2.1.8, https://cran.r-project.org/package=robis.
Pugh W (2021). UAIC Ichthyological Collection. Version 3.3. University of Alabama Biodiversity and Systematics. DOI: 10.15468/a2laag. Accessed via GBIF on 2020-10-13.
R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
Robins R (2021). UF FLMNH Ichthyology. Version 117.342. Florida Museum of Natural History. DOI: 10.15468/8mjsel. Accessed via GBIF on 2020-10-13.
Tavera L, Tavera M. L (2021). Biodiversidad de los recursos marinos y costeros entre Cartagena y el Golfo de Urabá, Caribe colombiano. Version 2.4. Instituto de Investigaciones Marinas y Costeras - Invemar. DOI: 10.15472/d2jusp. Accessed via GBIF on 2020-10-13.
UNIBIO, IBUNAM (2020). CNPE/Coleccion Nacional de Peces. DOI: 10.15468/o5d48z. Accessed via GBIF on 2020-10-13.
Wagner M (2017). MMNS Ichthyology Collection. Mississippi Museum of Natural Science. DOI: 10.15468/4c3qeq. Accessed via GBIF on 2020-10-13.
Werneke D (2019). AUM Fish Collection. Version 8.1. Auburn University Museum. DOI: 10.15468/dm3oyz. Accessed via GBIF on 2020-10-13.